
 отправка...
отправка...Оптимизация работы блочно-модульной системы обработки данных с использованием генетических алгоритмов
Рост потребностей в комплексной автоматизации делопроизводства предприятий, организаций и фирм обуславливает внедрение новых современных информационно-управляющих технологий, что в свою очередь приводит к обработке различной информации, возрастающей в несколько раз. Особенностью обработки информационных данных является то, что она осуществляется в реальном времени. Это накладывает определенные требования, предъявляемые не только к техническим средствам, но и к алгоритмам обработки данных. В этом случае необходимо разрабатывать алгоритмы обработки данных на основе современных подходов.
Процедуры обслуживания заявок в системах обработки данных реального времени (СОД РВ) зависят от времени поступления заявки на обработку, состава и взаимосвязей необходимых для ее обслуживания задач, а также от текущего состояния информационной базы, определяющего альтернативные возможности обработки данных.
Использование совокупности взаимосвязанных матричных и графовых моделей для анализа информационных потоков и технологии обработки данных в СОД РВ [1–3] в настоящее время из-за возросшего потока данных в инфокоммуникационных системах не позволяет оперативно их обрабатывать и управлять ими.
Поэтому предлагается строить алгоритм обработки информационных потоков данных в СОД РВ с использованием в начале традиционного подхода (матрицы и интегрированные информационные графы (ИИГ)), а на заключительном этапе — генетических алгоритмов (ГА).
Использование традиционных подходов [1–3] позволит сформировать полную и качественную информационно-управляющую структуру данных инфокоммуникационной системы. Применение же генетических алгоритмов даст возможность более оптимально построить процессы обработки информационных потоков данных в СОД РВ и управления передачей данных между абонентами инфокоммуникационной системы.
Обобщенной формой представления взаимосвязей информационных элементов, процедур при решении задач являются технологические матрицы сложности и достижимости, которые затем преобразуются в ИИГ обработки данных.
Построение и структуризация ИИГ для решения задач обработки данных реального времени осуществляется следующим образом.
Пусть задано множество задач СОД РВ {hn}, n = 1,—N—. Технологии решения каждой задачи соответствует направленный ИИГ Gn = (Dn,Rn), где Dn= {dln}, l = 1,—L—n; Ln — множество вершин ИИГ, отражающих информационные элементы задачи hn; Rn = {pr} — множество отношений между информационными элементами dln∈Dn. Каждому ИИГ Gn соответствует квадратная бинарная матрица смежности Cn = ||Cun|| размером LnxLn. Элемент ||Cun|| матрицы Cn равен 1, если элементы dln и dl′n графа Gn связаны отношениями pr, и равен 0 в противном случае.
Структурированный ИИГ взаимосвязей информационных элементов задачи, преобразованный к виду, не содержащему циклов обработки, называется скелетным ИИГ задачи и обозначается как Gcn. Он состоит из ряда уровней или непересекающихся подмножеств вершин, каждая из которых является выходным результатом обработки предыдущего уровня или подмножества информационных элементов. С использованием ИИГ Gcn определяется множество процедур обработки данных, необходимых для решения задач {hn}, n = 1,—N—.
Для каждой упорядоченной пары элементов (dln, dl′n)∈Dn определим подмножества:
D1n = {dln|∃dln((dln, dl′n)∈Dn)},
D2n = {dln|∃dln((dln, dl′n)∈Dn)},
D1n ∪D2n = Dn.
Затем определим на множестве Dn декартово произведение Dn = D1nxD2n. Пара элементов (dln, dl′n) связана с процедурой pr, если она принадлежит отношению Rn. Совокупность процедур задачи образует множество {pr} = Rn. Полное множество процедур анализируемого множества {ηn} задач определяется путем объединения:

Для определения в задаче входных, промежуточных и выходных данных, последовательности их получения и контуров обратной связи, а также анализа взаимосвязей в системе введено понятие матрицы достижимости.
Под матрицей достижимости Mn понимается квадратная бинарная матрица, проиндексированная одинаковым образом по обеим осям множеством информационных элементов Dn. Элемент dl достижим из элемента dl′(dlRdl′), если на графе Gn = (Dn,Rn) можно указать направленный путь от вершины dl к вершине dl′ (либо l = l′):

Матрица Mn определяется на основе матрицы Cn. При этом они связаны булевым уравнением:
Mn = Cmm+1 = Cmm ≠ Cmm–1.
Анализ структур обработки данных для каждой ηn задачи СОД и определение необходимой последовательности получения информационных элементов упрощается, если элементы построенной матрицы достижимости упорядочить по уровням (этапам) их обработки. Получение матрицы Mnметодом свертки циклов позволяет уменьшить ее размерность, облегчить анализ и синтез структуры решения как отдельных задач ηn системы, так и функционирования всей СОД РВ.
Взаимосвязь между процедурами обработки данных при обслуживании каждой заявки СОД РВ, а также между наборами входных и промежуточных данных удобно представлять с помощью таблицы инциденции [3] обработки множеств запросов Yn = ||yrln||, которая является матрицей вида.

В матрице Yn каждая строка отображает процедуру обработки, а каждый столбец — использование всеми процедурами при решении ηn задачи рассматриваемого информационного элемента. В строке содержится информация о множестве входных и выходных данных, связанных с анализируемой процедурой. Анализ столбцов позволяет выявить входные и выходные информационные элементы рассматриваемой задачи ηn. Элементы dl ∈Dn, l = 1,—L—n являются входными при решении ηn задачи, если dl столбец матрицы Yn содержит единственную, отличную от нуля запись yrln = +1, r = 1,—R—n. Если l‑й столбец содержит запись yrln = –1, то соответствующий ему элемент dl ∈Dn, l = 1,—L—n является выходным. Информационной матрицей смежности Cиn при решении ηn задачи назовем квадратную бинарную матрицу, проиндексированную по обеим осям множествами D1n ∪Rn. Матрица Cиnимеет четыре подматрицы — Cn, C1n, C2n, C3n с размерами DnxDn, RnxDn, DnxRn и RnxRn.
Используя матрицу Cиn, можно определить матрицу Mиn, которая содержит подматрицы Mn, Mn(1), Mn(2), Mn(3), проиндексированные соответственно DnxDn, RnxDn, DnxRn и RnxRn.
Подматрица Mn(1) удовлетворяет соотношение Mn(1) = C1nx(Cn)k = C1nx(Cn)k+1 ≠ C1nx(Cn)k–1, где k — целое положительное число, которое не больше числа Ln элементов при решении ηn задачи, то есть k < Ln–1. Матрица Mn(1)содержит единичные элементы в позиции (pr, dl), если процедура входит в последовательность, необходимую для получения элемента dl при решении ηnзадачи. В противном случае при записи в позицию (pr, dl) подматрицы Mn(1) она будет равна нулю. Подматрица Mn(2) определяется соотношением Mn(2) = MnxC2n и содержит единичный элемент в позиции (dl, pr), если элемент dl является входным для последовательности процедур, в состав которых входит процедура pr. В противном случае элемент (dl, pr) равен нулю. Подматрица Mn(3) является матрицей достижимости процедур обработки данных при решении ηn задачи и удовлетворяет соотношение:
(C3n)k–1 ≠ (C3n)k = (C3n)k+1 = Mn(3).
Единичная запись в позиции (pr, pr′) подматрицы Mn(3) соответствует наличию направленного пути в ИИГ технологии решения ηn задачи от процедуры prк процедуре pr′.
Построение единого ИИГ осуществляется путем выполнения операции «наложения» графов Gn и заключается в совмещении идентичных уровней каждого графа и идентичных вершин на каждом уровне. В результате формируется ИИГ G0, которому соответствует матрица смежности C0 = ||Cll′0||,l = 1,—L—, l′ = 1,—L—, полученная путем логического сложения матриц Cиn:
C0 = Cи1 ∨Cи2 ∨ … ∨Cиn.
Анализ структур полученного ИИГ позволяет на заключительном этапе определить следующие общесистемные требования к обслуживанию заявок в СОД РВ: множество требуемых задач обработки данных для обслуживания одного типа заявок и базовые задачи для каждого типа, взаимосвязи между заявками по решаемым задачам и между задачами по используемым процедурам и данным, рациональную дисциплину обслуживания заявок и оценку требуемой производительности вычислительной системы для заданной дисциплины обслуживания и др.
В качестве моделей описания и анализа задач обработки данных при создании типовых блочно-модульных СОД также используется аналогичная совокупность графовых и матричных моделей.
При формировании полного ИИГ технологии решения задачи обработки информационных потоков данных и управления ими можно учитывать всю необходимую информацию о взаимосвязях и отношениях между различными элементами отдельных задач.
Полный ИИГ и соответствующие ему матрицы смежности и достижимости позволят, применив ГА далее, более оптимально построить процессы обработки информационных потоков данных в СОД РВ и управления передачей данных между абонентами инфокоммуникационной системы.

Рис. 1. Схема генетического алгоритма
Основные принципы генетических алгоритмов (ГА) были сформулированы Голландом (Holland) в 1975 году и хорошо описаны во многих работах [4–6]. В общем виде генетический алгоритм может быть представлен в виде схемы, приведенной на рис. 1 [4]. ГА работают с совокупностью особей, каждая из которых представляет возможное решение поставленной задачи СОД РВ.
На первом шаге ГА формируется исходная популяция особей, где каждая особь представляет собой решение задачи, иначе говоря, является кандидатом на решение. Если рассматривать в качестве примера инфокоммуникационную систему, то под особью понимаются информационно-управляющие потоки данных (матрицы C, D, M). Формирование исходной популяции, как правило, происходит с использованием какого-нибудь случайного закона, в ряде случаев исходная популяция может быть также результатом работы другого алгоритма.
Для применения генетических операторов значения этих параметров должны быть представлены в виде двоичной последовательности, то есть двоичной строки, состоящей из нескольких бит. Количество бит при кодировании гена (хромосомы) зависит от требуемой точности решаемой задачи. Оптимальным считается такой выбор, когда выполняется соотношение:

где n — количество бит, используемых для кодирования значения аргумента; xmax и xmin — максимальное и минимальное значения аргумента x целевой функции; Δ — погрешность решения задачи.
Количество особей M в популяции определяется, как правило, эмпирическим путем, желательно из интервала n ≤ M ≤ 2n.
На втором шаге работы ГА происходит отбор, или селекция, наиболее приспособленных особей, имеющих более предпочтительные значения функции пригодности по сравнению с остальными особями. После чего к отобранным особям применяются операторы скрещивания и мутации.
В классическом ГА отбор наиболее приспособленных особей осуществляется случайным образом с помощью различных методов генерации дискретных случайных величин, имеющих различные законы распределения. Среди этих методов следует упомянуть пропорциональный отбор, отбор с вытеснением, равновероятный отбор и т. д. Каждый из перечисленных методов имеет как достоинства, так и недостатки, например, общим недостатком указанных методов является то, что при их использовании в некотором поколении наилучшие особи популяции могут быть потеряны. Одним из способов преодоления этого недостатка является использование сочетания алгоритмов отбора.
На третьем шаге реализуется операция скрещивания особей. Смысл этой процедуры сводится к нахождению новых комбинаций генетического кода хромосом путем обмена случайным образом участков генетического кода у двух особей, прошедших отбор. Это способствует «получению» дополнительного числа новых особей, среди которых могут оказаться как более, так и менее приспособленные особи. Это явление объясняется тем, что точка скрещивания выбирается случайным образом.
На четвертом шаге к особям популяции, полученным в результате скрещивания, применяется операция мутации. С помощью этой операции можно получать принципиально новые генотипы и фенотипы особи, что приводит к еще большему разнообразию особей в рассматриваемой популяции. Суть этого оператора заключается в следующем: в популяции случайным образом выбирается особь и так же случайно выбирается позиция гена, в которой значение изменяется на противоположное (0→1 или 1→0). Внесение таких случайных изменений позволяет существенно расширить пространство поиска приемлемых решений задачи целочисленной оптимизации.
Работа ГА носит итерационный характер, то есть все указанные шаги применяются многократно и ведут к постепенному изменению исходной популяции в направлении улучшения значения функции пригодности.
В качестве критериев останова работы ГА приняты следующие условия:
- Сформировано заданное число поколений.
- Популяция достигла заданного уровня качества. (Например, 75% особей имеют одинаковую генетическую структуру или одинаковое значение функции пригодности.)
- Достигнут некоторый уровень сходимости, при котором улучшение популяции не происходит.
Для решения поставленной задачи можно применить ГА, представленный на рис. 2.
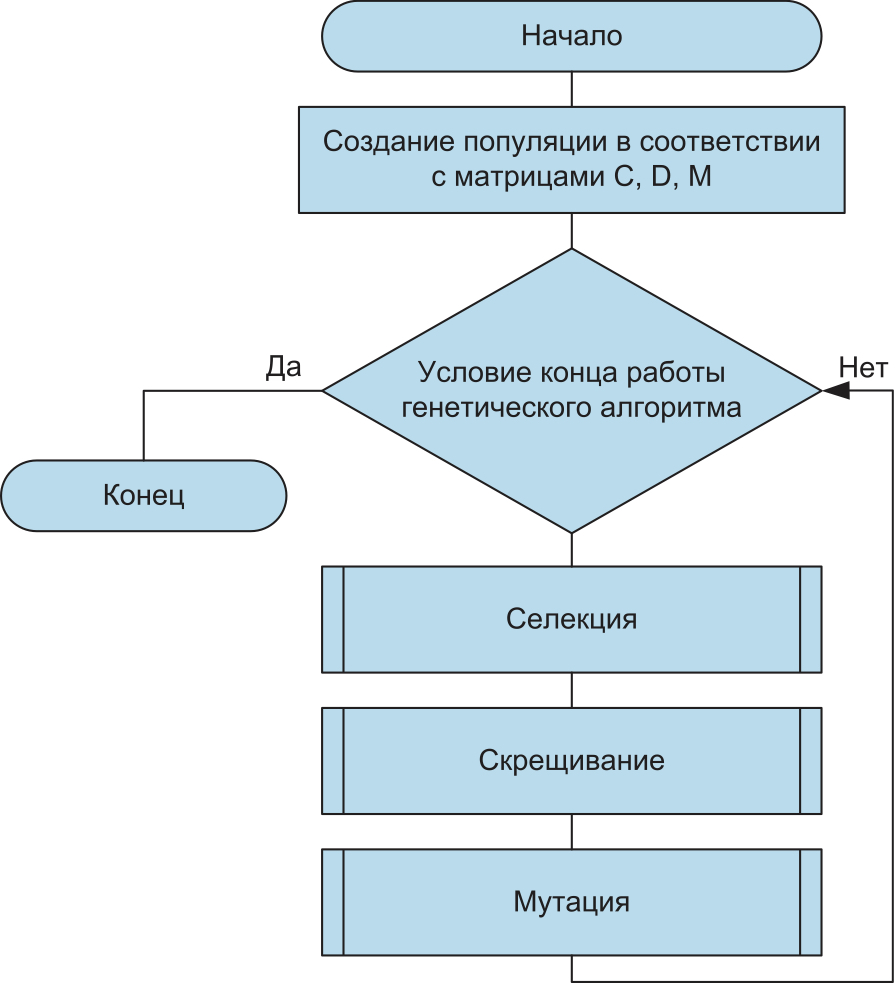
Рис. 2. Схема работы ГА
Модель отбора определяет, каким образом следует строить популяцию следующего поколения. Как правило, выбирают такую вероятность участия индивидуума в скрещивании, которая пропорциональна его приспособленности. Часто используется так называемая стратегия элитизма, при которой несколько лучших индивидуумов переходят в следующее поколение без изменений, не участвуя в кроссовере и отборе. В любом случае каждое следующее поколение будет в среднем лучше предыдущего. Когда приспособленность индивидуумов перестает заметно увеличиваться, процесс останавливают и в качестве решения задачи оптимизации берут наилучшего из найденных индивидуумов.
Возвращаясь к задаче работы блочно-модульной СОД РВ, поясним особенности реализации генетического алгоритма в этом случае:
- Индивидуум — вариант решения задачи: набор из 10 хромосом Xj.
- Хромосома Xj — технический или экономический параметр, влияющий на j‑ю структуру: 16‑разрядная запись этого числа.
Так как в любой инфокоммуникационной системе имеются ограничения на технические средства и информационные потоки данных, то не все значения хромосом являются допустимыми. Это учитывается при генерации популяций.
Приведем полное описание работы ГА:
- Создание структуры решения искомой задачи в виде массива a[i], i = 1, …, n, где n — максимальное число компонентов структуры.
- Создание показателя эффективности структуры, заполненной конкретными значениями.
- Задание некоторого массива различных структур Ck, k = 1, …, N, где размерность N больше, чем число компонентов n в структуре. Этот массив можно сгенерировать случайно, задав нули и единицы в каждой структуре.
- Расчет показателей эффективности Jk для каждой структуры Ck.
- Естественный отбор структур ИИГ по некоторому правилу выбора наилучших среди заданного массива структур. Пример: можно по правилу вида J0= M(Jk) определить среднее значение Jk. Если Jk < J0, то структура остается, иначе умирает. Если разница между J0 предыдущим и новым меньше какого-то малого числа, то расчет заканчивается.
- Замена выбывших структур на новые, рожденные от наиболее приспособленных структур с помощью генетических операторов:
- Мутация — замена в структуре одного из значений случайно выбранного компонента. Пример: из (1, 1, 0, 1, 0, 0, 1, 0) получится (1, 1, 0, 1, 1, 0, 1, 0).
- Инверсия — перестановка в структуре некоторой ее части наоборот. Пример: из (1, 1, 0, 1, 0, 0, 1, 0) получится (1, 1, 0, 0, 1, 0, 1, 0).
- Кроссинговер — создание структуры, основанной на двух структурах, — при замене одной части первой структуры на ту же область во второй. Пример: из (A, B, C, D, E) и (a, b, c, d, e) получится (A, B, c, d, E).
- Переход к этапу 4.
Влияние параметров генетического алгоритма на эффективность поиска оптимальной структуры СОД РВ
Стандартная схема ГА предполагает ограничение численности потомков путем использования так называемой вероятности кроссовера. Такая модель придает величине, соответствующей численности потомков, недетерминированный характер. Есть метод, предлагающий отойти от вероятности кроссовера и использовать фиксированное число хромосомных пар на каждом поколении, при этом каждая хромосомная пара «дает» двух потомков. Такой подход хорош тем, что делает процесс поиска более управляемым и предсказуемым относительно вычислительных затрат.
В качестве генетических операторов получения новых генотипов потомков, используя генетическую информацию хромосомных наборов родителей, применяют два типа кроссоверов: одно- и двухточечный. Вычислительные эксперименты [4] показали, что даже для простых функций нельзя говорить о преимуществе того или иного оператора. Более того, было показано, что использование механизма случайного выбора одно- или двухточечного кроссовера для каждой конкретной брачной пары подчас оказывается более эффективным, чем детерминированный подход к выбору кроссоверов, поскольку трудно определить, который из двух операторов лучше подходит для каждого конкретного ландшафта приспособленности. Использование случайного выбора позволяет сгладить различия этих двух подходов и улучшить показатели среднего ожидаемого результата. Проведенный вычислительный эксперимент показал, что случайный выбор оказался эффективнее.
Аналогичный подход применяется и при реализации процесса мутации новых особей, однако в этом случае преимущество перед детерминированным подходом не так очевидно в силу традиционно малой вероятности мутации. В основном вероятность мутации составляет 0,001–0,01.
- Кошелев В. А. Некоторые задачи синтеза оптимальных модульных СОД РВ. В кн. Теоре-тические и прикладные задачи оптимизации. М.: Наука, 1995.
- Кротюк Ю. М., Кошелев В. А. Синтез оптимальных модульных СОД РВ с относительными приоритетами // Вопросы кибернетики. Автоматизация проектирования систем обработки данных. М.: Научный совет по комплексной проблеме «Кибернетика», 1985.
- Белов Ю . В., Проценко В. С., Федоров В. В., Хижняк А. А. Индустриальные средства проектирования и оценки эффективности программных систем, работающих в реальном времени // Вычислительные системы и вопросы принятия решений. 2001.
- Гладков Л. А., Курейчик В. В., Курейчик В. М. Генетические алгоритмы. М.: Физматлит, 2010.
- Батищев Д. А. Генетические алгоритмы решения экстремальных задач. Воронеж: Изд-во ВГТУ, 1995.
- Джонс М . Т. Программирование искусственного интеллекта в приложениях. М.: ДМК Пресс, 2004.
 15 марта, 2021
15 марта, 2021